半角/全角とは
日本語で使用される文字は、半角/全角という考え方があります。
同じ 文字サイズで 印字する場面に おいて、その縦横が 正方形ならば 全角、半分なら 半角、ということになります。
Window系のJIS キーボードでは「半角/全角」キーがあるので認識しやすいですが、それ以外の装置で入力する人には あまり意識されないかも知れません。パソコンを使わずスマートフォンのみの人だと、全半角は まったく意識しないかもしれません。もちろんFAXを使っていたり 手書きする場合には そんな区別は ありません。
コンピュータで使用可能な全角文字には おおむね 次のようなものがあります。
- 全角ひらがな
- あかさた… わゐゑをん
- がざだばぱ… ゔ
- っ ぁ ゃゅょ ゎ
- 全角カタカナ
- アカサタ… ワヰヱヲン ー
- ガザダバパ… ヴ
- ッ ァ ャュョ ヮ ヵㇰヶㇱㇲㇷ゚ㇴㇺㇿ
- 全角英数字、記号(欧文由来)
- ABC 123 %&!?+=〜/¥$:
- 漢字、その他全角文字 記号
- ☆→←▲■※㈱㌦「」・、。
これに対して 半角は あまり多くなく、およそ次のものが該当します。
- 半角英数字・記号
ABC abc !? %&$ ()/\=- ,. - 半角カタカナ・記号
アイウエオ ワヲン ッャァォ ー¥ 、。
全角半角は、数字やアルファベット、記号「 ( ・ なども含めて両方存在するものがありますが、片方にしか無いものもあります。
半角英数字について「半角」というのは、全角を用いている日本語の都合で、他の言語では大文字小文字とか、固定幅か 可変幅かというフォントの区別はしても、元々同じ文字自体を 幅だけで区別はしません。
どの文字が全角か半角かは 呼び方が そうであっても、必ずしも絶対ではありません。あくまで その分類の文字を、そう 印字されるように 設定した 媒体でのみ 言葉通りの機能を持ちます。
半角全角の誕生
半角カタカナ(Harfwidth Katakana) は、もとは古い電子機器で印字されてきた文字種のひとつですが、最初はそのような呼称はありません。
日本の電子機器普及の初期の工業規格 (JIS 0201) に含められたもので、固定幅で 横書き表示されてきたものです。
電子情報機器での文字の規格として最初にできたのは ASCIIというアメリカのもので、英数字といくつかの記号を含めた 0~127までの 7個の電気信号(ビット) からなるものですが、これに拡張を加えたものです。
のちに、電子機器上で 漢字などの多種の文字を扱うようになるにつれ、追加の規格と混ぜ合わされ、同じカタカナに対して半角と全角の両方が、コンピュータのデータ上で別の文字として扱われるようになりました。
日本語で使われる文字は、漢字・ひらがな・カタカナ・数字・記号など種類も多く 日常的に利用されるものでも 軽く1000種類を超えます。
もともと 経典の写経や 漢詩など 一部の分野では縦横に全角文字を整列させることを 美とするような世界もありますが、庶民には 必ずしも一般的ではありませんでした。複雑な漢字を小さく書くのは難しいですし、逆に簡単な文字を漢字に合わせると 紙が もったいない からです。
その辺りのルールを変えたのが 活版印刷にあります。多数の活字 (金属製の文字のピース) を 版として組んだり、あるいは整理して収納するのには、サイズがすべて同じ方が都合がよく、そのことから「全角」という一種の 印刷のための技術が 普及するようになりました。
初期の電子機器の規格は漢字は扱えず、銀行振込であるとか基幹業務・メインフレームのためのもので、デジタルの文字の幅は一種類で、印刷とは別の世界です。それが 入力した文字を記録するフロッピーディスクのような持ち運べる記録媒体や、かな漢字変換のような技術が誕生し、ようやく電子機器上で漢字を使うことが実用的になり、その時期に全角を標準とする印刷系の用途と交わるようになります。
当時の全角文字は、半角英字やカタカナで用いる1バイト(8ビット) では収まらないため、2バイトで 記録するようになりました。コンピューターで 画面に文字を印字するには、データの何番目が どの位置に表示されるか計算する必要がありますが、2バイト文字を半角のちょうど2倍で表示すると、この計算が簡単にできるという利点も得られ、双方に都合が良かったのです。
現在ではインターネットが普及し、文字は印刷せずにデータのまま送るようになり、文字の大きさは読み手が変更可能なため、全角か半角かという区別は 再び意味を 失なってきています。
また印刷のほうもデジタル化が進んでいて、幅の異なる文字が混じっていても 自動調整が可能となり、もはや この区別は 無意味になってきています。特に アルファベットや数字が混じった文章では、半角という固定幅ではなく 文字によって幅が違う 欧文フォントのほうが バランスが良く、日本語の部分だけ幅を固定しても 全体として うまく整いません。
全角固定幅の英数字が役立つのは 新聞や 昔ながらの縦書きくらいで、半角カタカナと日本語半角記号(「 、 ゙ など)は、どうしても小さく書きたいとか、顔文字のような特殊な状況に限られます。
印刷に詳しくない一般の人からすれば 半角/全角の区別は ややこしいだけで、自動的にコンピュータの側が認識して 適切な幅で処理してくれたほうが楽でしょう。
半角カタカナの不運
半角カタカナは、初期のコンピュータでの表示を目的としたものであるため、当時の必要最小限の文字しか含んでいません。以下のものが全てです。
アイウエオ カキクケコ サシスセソ タチツテト ナニヌネノハヒフヘホ マミムメモ ヤユヨ ラリルレロ ワヲンァィゥェォ ャュョ ッ ・ 、 。 ー ゙ ゚ 「 」
鍵かっこ「 」とか中黒・などは全角以上にコンパクトで使いやすいものも あるのですが、ヰやヱのような文字がなかったり、やや不足があります。
特に濁点゛と半濁点゜が 独立した文字であるのが 難点です。このため 濁点を含む単語 「ショウガッコウ」などと書くと、濁音部分だけ 2字になって 幅がおかしくなります。
濁点を別の文字にしているのは、1バイトで表現できる範囲(255種類)で濁音 ガギグゲゴ 〜 パピプペポ 25字を追加すると、もともとある 英数字領域と合わせると 大部分を 使い切ってしまうためです。
また7ビットしか扱わないシステムで データを読み込んだ際に 誤動作の可能性のある 特殊な制御信号を含む 0〜32 (0x20) の領域を使わないようにするなど互換性を高めるという狙いもあって、必要最小限としたこともあります。
この 互換性 というのが キモで、コンピューターの世界では 何らかの他の古いシステムと 同時に使った際に お互いに悪影響を与えないようにするというマナーが要求され、その古いシステムが 絶滅するまでの間は 別の誰かが間接的にその負担を背負うことになります。
一般に、ソフトウェアと比較してそれで作成したデータは、はるかに長期間保存されます。1バイトのみで 構成される古いデータは そのまま読み取れるように しておきたいという要求があり、いっぽうで それと同時に 新しいことを実現したいという要求もあり、その両方を実現しようとすると 複雑なデータ構造が 生まれてしまうのです。
このころの半角カタカナは 0xA1〜0xCFの 領域を使うため、 7ビットしか扱えない環境では共存できません。8ビット目(1バイトごとに区切った先頭または末尾) を 何かのスイッチ として用いるシステム、特に機器間での通信制御信号と重なるケースは 相性が悪かったわけです。
時代が進み全角が一般化するにつれ、この考えは別のルートをたどるようになります。規格EUC-jpは、7ビット制限に対応するために 半角カタカナを 2バイト文字として 別の場所に移動しました。
対して Shift-JIS では、逆に 2バイト文字の頭1バイトを 半角カタカナと重ならないように 区画の一部をスキップして格納するようにしました。
Shift-JIS を使うソフトウェアであれば、半角カタカナを含むデータを 変換処理なく素早く表示できます。しかしEUC-jpで データを読み取ろうとすると、文字化けしてしまいます。
このあたりから 日本語の文字コード関係で人々が もめるようになります。最初のうちはまだ専門家だけの問題でした。しかし 1990〜2000年あたりで 日本でインターネットが大きく普及していくころから、この文字セットやエンコーディングがどうという話が 面倒なものとして認知されていくようになります。
さらに厄介なことに、 ShiftJIS や EUCで扱われている文字だけでは まだ足りないという人々も出てきます。日本語には旧字体や異体字を含めると万単位の文字があり、全部が収めきれないのです。
ここで、半角カタカナとの衝突を避けるようにしたという当初の設計を やめるべきではないかという考えがだんだん出てきます。そうすれば A100〜DFFF が利用可能となりもっとたくさんの文字を2バイトで格納できるからです。
この考え方の根底にあるのは、全角カナがあるのだから 半角カナなど使わなくても よいではないかという 半角カナ不要論です。すべてのデータを全角にしてしまえば、互換性など無視できるようになるであろう と、半角カタカナを 消し去ることを良しとしたのです。
こうして、入力システムの様々な場所に「半角カタカナは使用しないでください」という表記が出回るようになります。プロではない一般の入力者に注意を呼びかける姿勢は、教育的な意味もあるのかもしれないですが、実際にはストレスになります。システム異常を引き起こす文字は 他にもあるのですが、半角カナはその代表として 不当に 忌み嫌われるようになります。
そうこうしているうちに現れた思わぬ伏兵が Unicode です。
こちらは 日本国内の個別の事情とは別にして、世界中のすべての文字を ひとつの方式に統合しようという、もっと野心的な 思想のもとに 生まれた 文字体系です。
このシステムは、あらゆる文字を 統一規格で 使えるようにしたいという 世界の人々の期待を叶えるべく現れたものですから、そこには 不要な文字を廃止しようというような 縮小的な考えがありません。
日本語のカナに 半角と全角があるのだったら 両方とも含めてしまえ とばかりに、そのまま整理統合されることなく 世界の波に吸収されてしまったのです。
なんでも すべてを吸収していく世界規格に 日本独自仕様は対抗できません。カナを 統合すべきではないかというような 議論は置き去りにされてゆきます。
やがて日本では iモードなどの登場により、文字入力はモバイルへと フィールドを移し、あらゆる人々へと一般化していきます。人々の文字への関心は カナの全角半角のような オタク的で地味なものよりも、絵文字とか あるいはスタンプのような リッチな方へとシフトしていくようになります。
当初の携帯電話では それぞれが独自の 文字コードを用いていましたが、後に現れた 世界規格のスマートフォンでは、当然 世界を視野に入れた Unicodeが使われています。その圧倒的な普及力に、もはや 古い文字コードを使おうなどという動機は 一般的には消滅してしまいました。
こうして 半角カナは生き残ることに なりました。ただ、古いシステムのあちこちに「半角カタカナは使用しないでください」という呪いの言葉が 刻まれているため、理由はよくわからないが 使ってはいけないものという認識もまた残っています。
フォントと戯れる
半角カナが 嫌われる原因のその最たるところは 歴史的なものにあるわけですが、しかしその一方で 見た目に起因するところもあります。
カタカナは もともと漢字の一部を切り取ったものですから、半角だと漢字が半分だけ書かれたように誤認するおそれがあります。たとえば イ ヒ は 化、タ トは外、シ タ は汐などと、組み合わせによっては 分かりづらい場合があります。
前述のとおり、半角カナが そのフォルムを 顕わすのは、あくまでそのように設定された状況があってのことです。
例えば、半角カナ部分に 適用するフォントを変更すれば、その問題は解消できます。
考えうるフォントとしては、幅を漢字の70%程度にして一字に見えるようにする、英小文字のように高さを下げて位置関係で文字種を示す、ヒンディー語などデーヴァナーガリー文字のシローレーカー( हिन्दी など)のように補助的な線画を加えてカタカナをマークする、などが挙げられます。
半角カナは 記号含めて全部で 63種であるので、自分で作ってしまうというのも そこまで難しい作業ではありません。
フォント制作にはいろいろな手段がありますが、その中で 比較的 手軽なのは FontForge というフリーソフトを用いることです。
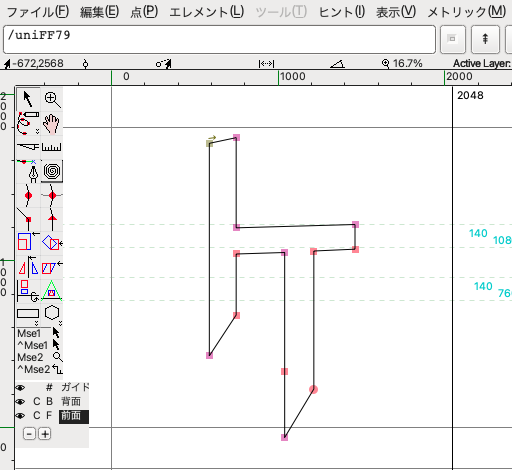
画像は FontForge の 文字編集画面ですが、よくあるパス (輪郭線) 編集ツールでフォントを書くことができます。また 別の編集ソフトでパスを書いて SVGなどの形式で書き出してやれば、それを読み込ませることもできます。
半角カタカナは Unicode では uFF61〜uFF91 の位置にあります。それ用のフォントを作りたければ、そこに好きな形状を登録すれば良いということです。
フォントを使った テキスト編集は、多くの場合は文字ごとにフォントを指定するものが多いですが、Webサイトのような 不特定多数が利用する環境においては、優先するフォントから順に複数指定することができます。
フォントファイルの中に、半角カナの グリフ (字形) だけが登録されている場合、第1フォントとしてそれを指定し、第2フォントとしてそれ以外のものを指定しておくと、半角カナだけにそのフォントを 一括で適用するということが できます。つまり全部の文字を作る必要はないということです。
また逆に、フォントファイルの中から 半角カナだけを 消したり、最初から無いものを 第1フォントとして 選ぶこともできます。そうすると 抜けた部分に 第2フォントを適用できます。
手始めに カタカナの部分だけ登録した適当なフォントを用意してみます。調整が難しくなるので ここでは直線のみでフォントを形成してみます。また半角で邪魔な 縦書き由来の 斜めのストロークは、識別に必要な部分以外は垂直にしています。
フォントには カーニングペアという、隣接する特定の2字の字詰めを 個別に設定する機能があります。上の枠のフォントには 半角カナに続く濁点に、文字幅と同じ値をマイナス設定の字詰めが設定してあります。
同じテキストで 特別なフォントを指定していないと、次のようになります。
カーニングペアを使った例では半角カナの濁点の位置は 横に突き出ぬように 調整されていますが、通常のフォントではガギグゲゴの幅が 広くなってしまっています。
またさらに、半角カタカナが登録されているコード ポイントに 全角カタカナと同じグリフを登録すると、下のように全角も半角も見た目を同じにすることもできます。
上のテキストを別の場所にコピーすれば、全角半角が混ざっていることが確認できるでしょう。
リガチャー
フォントを細工してできることは、濁点の調整だけではありません。特に面白いのがリガチャー(ligature) という機能です。
リガチャーは 合字とも呼びますが、特にアルファベットで ffとか fi のように横に伸びる線が続くときに連結させたりする デザイン上の技法のことです。文字種が少ない 英文用フォントでは これが設定されているものが しばしば見受けられます。
この機能は 日本語でも利用は可能です。 正方形で 固定幅を基本とする 日本語フォントでは あまり多くは ありませんが、毛筆での手書き風の 縦書きフォントなどでは 時々これに出会うことがあります。
漢字がある日本語では 文字の組み合わせが 天文学的な 数になるので、うかつに手を出すと 沼に はまってしまうのですが、カタカナに限って対応するなら 2000パターンあまりなので、不可能ではない数です。少なくとも漢字フォントを全部作るよりかは楽でしょう。
このリガチャーについても FontForge で作成することができます。
半角カナが あまり使われないということを逆手に取ると、このリガチャーを利用して 様々なことができます。
下の例は、ローマ字式カナづかいで入力したテキストに対して、対応する全角カタカナを出すように 仕込んだものです。全角1字に見える部分は 実は 半角カタカナ2字です。カ キ ク ケ コに 見える部分はクア クイ クウ クエ クオと書いてあります。
この例自体は 実用的な例では ないですが、見た目と 実際に書き込まれたテキストが 一致しなくてよいという特性は、応用の可能性があります。
例えば上のテキストをコピーして 別のところに貼り付けると分かりますが、この記法で 文章を書いて 公開すれば、別の場所に 流用されることを いくらか妨害できます。フォントが変わると 別の字になるからです。AIとか クローラーの類が サイトのデータを勝手に収集することに対して、それらを騙すような用法もあるかもしれません。
他の例としては、何かのキーワードに対して オリジナルの絵文字やアイコンを 表示するといったことも 考えられます。“ハート” と書くと “♥” が表示されるみたいなことです。アイコン以外の場所には 常に全角カナを使うようにしていれば、予期せぬ場所で アイコンが出て 困ることもありません。この技法は、テキスト読み上げ機能を使ったときに アイコン名を読み上げてくれる効果もあります。
フォントの編集は 緻密な作業で時間がかかりますが、慣れてくれば だんだん楽しめるようになります。自分の名前や 店のロゴやメニューを作ったり、何かと利用できる場面もあるでしょう。もし試したことがなければ一度やってみると良いかもしれません。
異体字セレクタ
濁点や 幅の問題については、フォントが助けになるということは分かりましたが、それでも どうにもならない部分が まだ残ります。それが 全角にある一部の文字が半角に不足しているということです。
- 旧ワ行の一部
ヰヱ - 特定用途小文字
ヵヶ - 合拗音用
ヮ - アイヌ語用小文字
ㇰㇲㇳㇷㇹㇷ゚ㇽㇼㇺㇴ
これらの文字を 半角で表示したいという要求が いかほどあるかは 明らかではありませんが、純粋に機械的にカタカナを拾って すべて半角化するようなプログラムを動かすときに、これらの文字が含まれていると エラーが起きたりしてしまうという点があります。
半角カタカナが 登録されている Unicodeの番地は隙間なく詰まっているため、ここに多数の新たな文字を 割り込ませるのは無理があります。そこで考えうる方策としてあげられるのは 異体字セレクタ(VS)の活用です。
異体字セレクタは 日本語の旧字体などの異体字や 絵文字などで多く使われている 文字合成の手法の ひとつです。ちょうど これは カ+゛=ガ とするのと 似たようなもので、特定の文字(コード)を 並べたときに 別の文字を 表示することができます。
厳密には異体字セレクタは それ単独で表示できず、濁点とは 似て非なるものですが、プレーンテキスト データに 埋め込んで 保存が 可能です。
ヰに対応する半角カナを 出したければ、ヰ+(半角化) という2字を並べれば良く、あとは それに対応するグリフを フォントの方に登録しておけば 実現できるだろうということです。
ただ残念ながら 現状は (半角化) なる VS は規定されていないため、そのような使い方をしても 他の環境にデータを送っても再現はできません。半角のそれを使いたいという要望が 多数 あがらないと 規格化は実現されないでしょう。
さりとて技術的に実装自体は難しい内容ではないので、絶対に無いとも言い切れないでしょう。
カナの後ろに VS16などを 適当に付けたデータを 送ったからといって、たいていは無視されるだけなので、私的な通信や 了解を得た上で用いる限りは 問題にはならないでしょう。Webサイトの場合は フォントも含めて公開する分には 自由です。
この実装は、技術的に別の利点もあります。
ひとつは、半角/全角 変換システムを作る場合は、単に VSを 付与/削除 するだけで良く簡単になります。プログラミングで これをするには “\uFE0F” のような エスケープシーケンスを カタカナの後ろに追加/削除すれば良いということです。
全角半角が混在するような データベースから キーワード検索するような場合でも、VSを削除して検索するだけで良いので、1文字ずつ 対応する文字を割り出して 置き換えるよりも ずっと効率よく検索できるでしょう。
また仮に もし未来に カタカナが増えた場合は、自動的に半角も 対応できます。Unicodeの新たなブロックを 半角用に 増やす必要が ないということです。
将来的に 仮にすべての半角カナが VSで実現されるようになれば、既存の半角カタカナのコードを 廃止することもできます。半角カナ廃止論の夢が 形を変えて実現するということです。
ここで、半角カタカナに cmap マッピングしたフォントの例を載せておきます。1行目は普通のカタカナ、2行目は半角カタカナ、3行目は 全角カタカナの各文字に VS16 を添えています。上下段で幅が違うのに、別の場所にテキストをコピーして幅が同じになれば それは異体字セレクタの効果です。
この半角カナを拡張するのは文字の種類を減らして 日本語を簡単にしようという考え方とは ベクトルが異なるように見えます。
しかし全ての文字に 全角半角ペアが 存在すれば、機械的に変換をかけてもデータの欠損は起こりません。一度入力したテキストの全角半角を 手軽に安心して切り替えられるということになり、扱いやすくはなるでしょう。